This section applies only to VoiceXML applications that use Japanese, Cantonese, or Simplified Chinese.
The Spelling~Soundslike notation is only supported for the Japanese and Simplified Chinese languages in WebSphere Voice Server. It is not supported for Cantonese.
A single word may have several pronunciations. For example, the
Japanese word 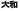 can be pronounced as “Yamato”
and “Daiwa.” Subsequently, when the TTS engine receives this word
for synthesis, it cannot accurately determine which pronunciation
to use.
can be pronounced as “Yamato”
and “Daiwa.” Subsequently, when the TTS engine receives this word
for synthesis, it cannot accurately determine which pronunciation
to use.
To solve this problem, you can specify a sounds-like spelling in a grammar for a word so that the TTS engine can return the word's correct pronunciation to the user. The format of the notation is Spelling~Soundslike. For example, if you want to pass the sounds-like pronunciation “drive” for the word “Dr”, specify the following in the grammar:
<name> = Blvd | Ave | Dr~Drive
When the speech recognition engine receives the utterance “Drive”, it will return the word “Dr~Drive” as the recognition result for the utterance. The VoiceXML browser saves “Dr~Drive” in the utterance shadow variable. (See Table 1.) If the recognition result is used for a prompt, “Dr~Drive” is passed to the TTS engine, which uses the sounds-like information, if necessary.
A VoiceXML document like this:
<?xml version="1.0" encoding="iso-8859-1"?>
<vxml version="2.0" xmlns="http://www.w3.org/2001/vxml" xml:lang="en-US">
<form id="address_form">
<field name="my_address">
<grammar version="1.0" type="application/srgs">
#ABNF 1.0;
language en;
mode voice;
root $street;
$street = Main Boulevard | Main Avenue | Main Dr~Drive;
]]>
</grammar>
<prompt> Where do you live? </prompt>
<filled>
<prompt>
You live along <value expr="my_address$.utterance"/>.
</prompt>
</filled>
</field>
</form>
</vxml>
results in the following dialog:
|
- In Japanese, the Soundslike pronunciations must be given using Hiragana characters.
- In Simplified Chinese, Pin Yin needs to contain a white
space in a sounds-like spelling. To distinguish a white space in a
sounds-like spelling from the white space of a delimiter, use an underscore.
For example:
Spelling~Wen1_Yan1
- In Cantonese, Yue Pin (LSHK) needs to contain a white
space in a sounds-like spelling. To distinguish a white space in a
sounds-like spelling from the white space of a delimiter, use an underscore.
For example:
Spelling~Biu2_Daan1_Kap1