- The call interaction is easier and more natural.
- Callers who are using a cellular (mobile) or hands-free telephone don't have to remove it from their ears to continue the interaction.
- Applications can be designed specifically to accurately recognize times, dates, and currencies.
- The overall time taken to complete transactions is reduced.
The simplest speech recognition applications enable callers without push-button (DTMF) telephones to use equivalent applications. The technology can also be used to provide more sophisticated applications that use large vocabulary technologies. For telephone applications, speech recognition must be speaker-independent. Voice applications can be designed with or without barge-in (or cut-through) capability.
Speech recognition is particularly useful if a large number of your callers do not have DTMF telephones, if the application does not require extensive data input, or if you want to offer callers the choice of using speech or pressing keys.
Figure 1 shows a typical speech recognition setup. To handle the processing that speech recognition demands, the example uses multiple LAN-connected server machines.
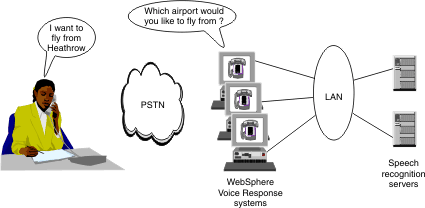
- The speech being processed is received from telephone lines rather than a microphone. The speech recognition has, therefore, to cope with the lower quality speech that is associated with the limited bandwidth and sensitivity of telephone systems.
- Instead of being trained to a single user, speech recognition technology has to adapt to the different voice characteristics of many different callers, operating in a speaker independent manner.
Speech recognition using an MRCP Version 1-compliant speech recognition product
Speech recognition by MRCP Version 1-compliant speech recognition products is supported in both the VoiceXML and Java programming environments. The runtime components of WebSphere Voice Server or other MRCP Version 1 compliant speech recognition product such as Nuance Speech Server version 5.1.2 (Recognizer 9.0.13), or Loquendo Speech Server V7 work with the speech recognition engine to perform the recognition. Recognition engines can be distributed across multiple systems so that resources can be shared, and redundancy is provided.
To allow highly-accurate recognition of continuous speech in this environment, the speech must follow a format that is defined by the application developers. These formats (or grammars) can allow many possible ways of speaking requests, and many tens of thousands of words can be recognized. Although WebSphere Voice Server provides the means for you to support large-vocabulary speech recognition, the system does not allow dictation.
The WebSphere Voice Toolkit enables an application developer to create the grammars that perform the recognition. The grammars can be created in multiple national languages.
http://publib.boulder.ibm.com/infocenter/pvcvoice/51x/index.jsp
Planning a speech recognition system
- The number of gateway systems you require to connect to the speech server
- The number of automatic speech recognition (ASR) engines and how many will be active at any one time.
- The number of text-to-speech (TTS) engines, and how many will be active at any one time.
- The number of machines you require, as a function of the number and speed of the processors available in each machine.
- The type of local area network necessary.
Application load
To estimate the application load on the system, you need to know the following:
- The number of telephony channels required to handle the number of calls you expect for applications using MRCP Version 1-compliant speech technology. You must consider how long on average each caller is expected to wait before being answered.
- The call frequency and distribution – whether the number of calls
likely to be made is the same throughout the day, or if the call pattern
is likely to vary significantly, with peaks and troughs in demand.
Your MRCP Version 1-compliant speech technology system should be able to handle the maximum demand for speech resources. That is, the resources needed at the peak calling hour rather than a day's average number of hourly calls. The primary speech resource is the ASR or TTS engine. The demand for engines is influenced by both the frequency of calls and how they are distributed. If all the incoming calls use the same application and start at the same time, each call will need an engine at the same time so the demand will be high. If, on the other hand, calls are distributed normally, the number of engines needed simultaneously can be considerably smaller.
For your applications, you must determine the acceptable performance or desirability of an engine being available for a call without a significant delay. Delays can cause performance degradation, such as not recognizing speech input or stuttering output. If a degradation of performance is acceptable during peak utilization, fewer engines will be required.
- The time that engines are allocated, or assigned, as a proportion of a call. This is known as the allocation duty cycle, and depends on how the engines are allocated. Some voice applications allocate engines dynamically for each utterance, others allocate engines when first required and free them only when they are no longer required or at the end of the telephone call.
- The time that engines are active (recognizing speech or synthesizing
text to be played) as a proportion of a call. This is known as the active
duty cycle. This can vary considerably, depending on the design
of your voice applications and their complexity. These factors determine
the number of concurrent ASR and TTS sessions that are required.
The number of concurrent ASR and TTS sessions, in turn, determines the number of processors required and how powerful they must be. Similarly, these two variables – number and speed of the processors – dictate the number and size of the machines needed for your MRCP Version 1-compliant speech technology installation.
For example, a non-barge-in application using long prompts of synthesized text together with a simple grammar is likely to be actively engaged in recognition for only a short proportion of the length of a call. It will have a short active duty cycle for ASR but a long active duty cycle for text-to-speech.
A barge-in application using shorter prompts of synthesized text together with a complex grammar is likely to spend more time actively engaged in recognition. In this case, the active duty cycle for ASR will be longer and the active duty cycles for text-to-speech shorter. If a system is under-specified, an engine might not be available at the start of a call.
For optimum performance with applications using complex speech recognition, it is recommended that an engine be assigned at the start of a call and freed only at the end of it, so that the caller uses the same recognition engine throughout the call. Grammars then only need to be loaded once, thus increasing the speed of processing.
Allocating speech recognition and TTS engines
The following figures illustrate the sequence of events in different types of voice application using speech recognition and text-to-speech:
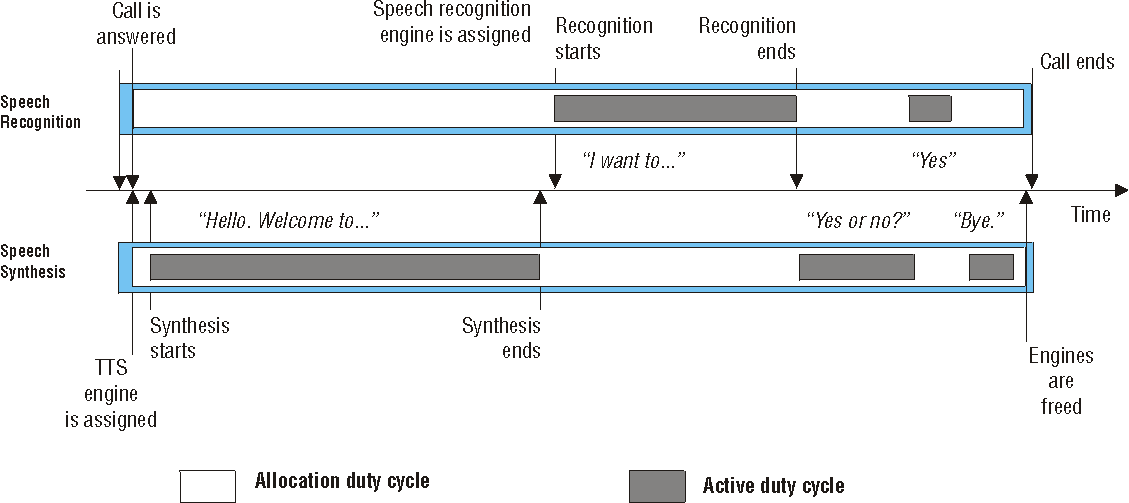
With a non-barge-in application, text-to-speech engines are allocated for the duration of a call, and speech recognition engines are allocated slightly before the first period of speech recognition until the end of a call.
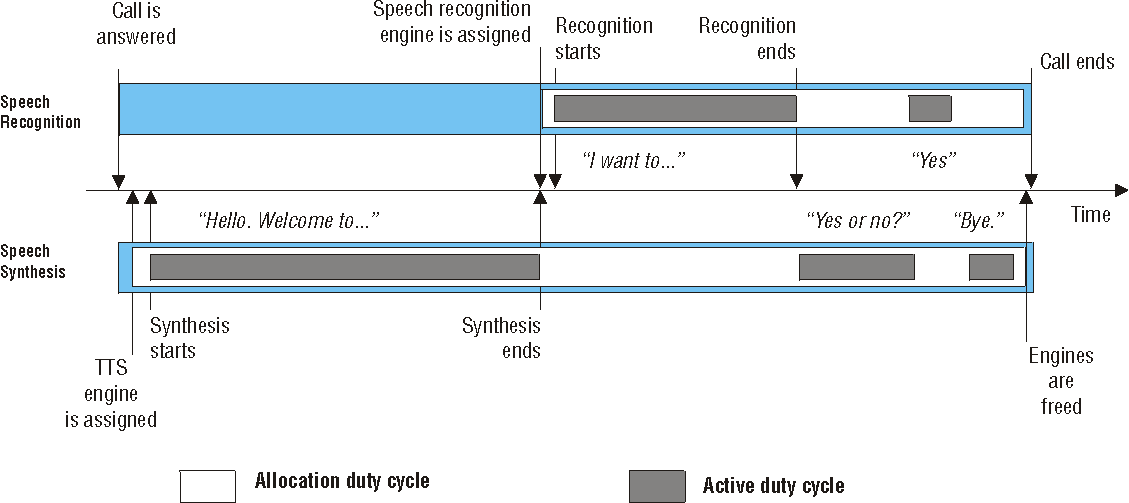
Depending on the application load on the system, and the number of engines in your speech recognition system, to optimize the use of speech recognition or TTS engines, you may choose to allocate engines dynamically rather than allocate engines for the duration of a call. With dynamic engine allocation, speech recognition and TTS engines are allocated slightly before each period of speech recognition or text-to-speech begins, and the appropriate engines are freed slightly after each period ends. The disadvantage of using this approach is that an engine may not be available when required by a voice application. Also, the vendor of your speech product may not support the use of a dynamic engine allocation approach.
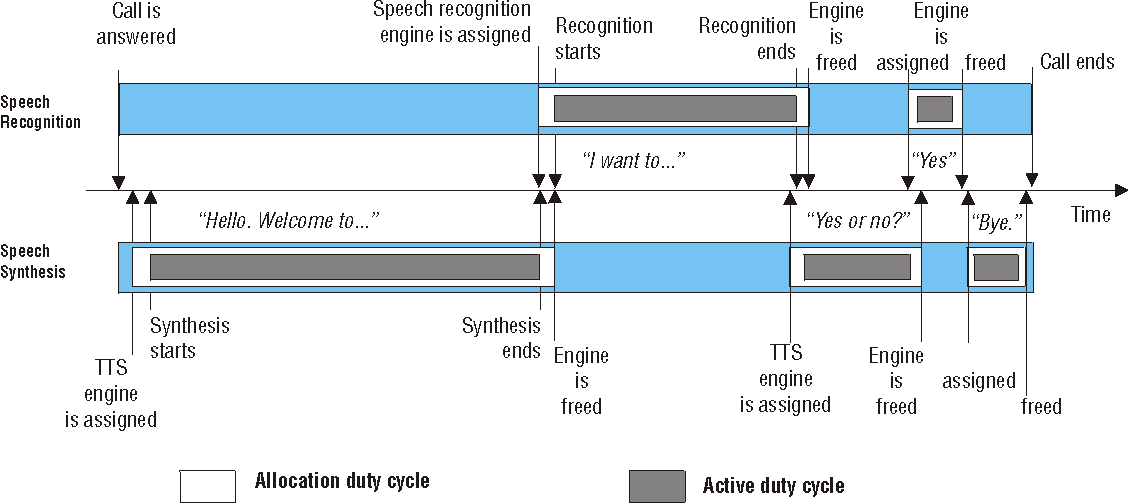
For information on configuring speech recognition using dynamic engine allocation, see InitTechnologyString.
For information on configuring text-to-speech using dynamic engine allocation, see InitTechnologyString.
To optimize the use of speech recognition or TTS engines, you can also close a speech recognition or text-to-speech session directly from a VoiceXML document by using the <object> element.
See Closing a speech recognition or TTS session from VoiceXML